
The Category Label Trap
Three brands, three Western analogs, and the translation failure AI cannot see — plus one corrective experiment that backfired.

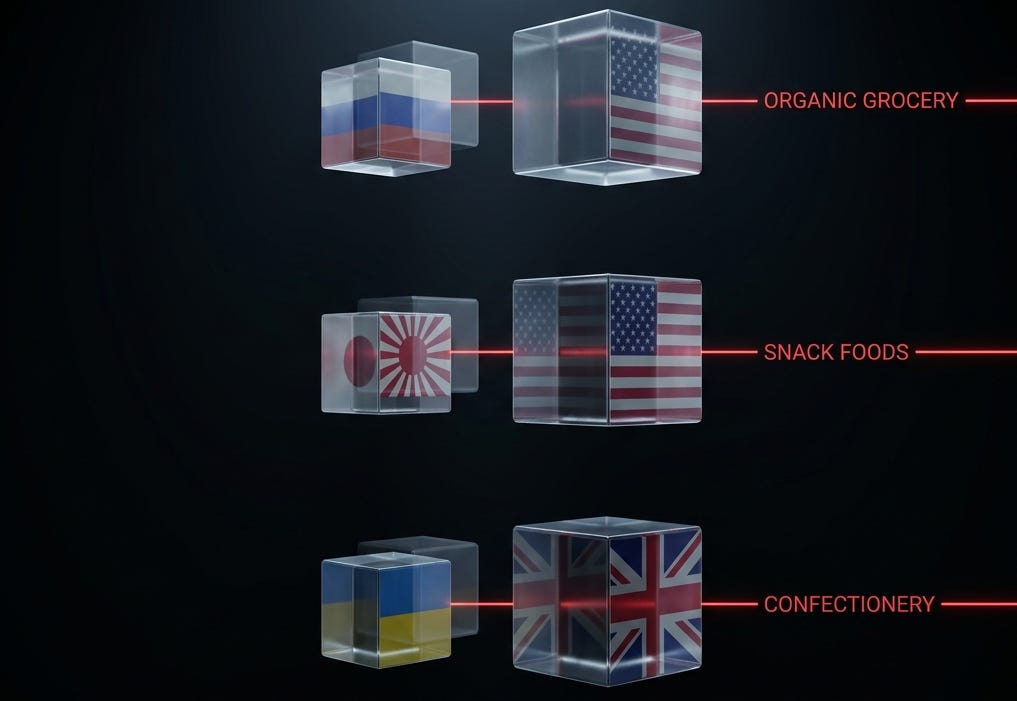
Quick orientation for anyone new to this work. AI assistants are becoming the default brand-research tool. When someone asks ChatGPT, Claude, Gemini, or DeepSeek to compare two brands, the model has to translate each brand into the categories it understands. For dominant Western brands the translation is mostly accurate — the AI has read enough about Whole Foods to describe Whole Foods. For non-Western category champions the translation breaks: the AI reaches for the closest dominant analog and silently substitutes its structure. As more buying decisions get routed through AI assistants, that silent substitution becomes a structural disadvantage for any brand that does not own the category template AI was trained on. This article documents three cases of the substitution and one experiment we ran to see whether handing the AI a better comparator would fix it.
Russia’s largest clean-label grocery chain operates over 1,350 stores across 72 cities. Japan’s most distinctive snack maker has been shaping the country’s snack culture for almost seventy years. Ukraine’s confectionery conglomerate spans chocolate, biscuits, cakes, and jellies under one corporate roof.
When you ask an AI shopping agent about any of them, you do not get back a description of the brand. You get back a translation. The AI sees a category label and reaches for the dominant Western brand that owns that label. VkusVill becomes “Russian Whole Foods.” Calbee becomes “Japanese Frito-Lay.” Roshen becomes “Ukrainian Cadbury.” None of these translations is correct, and the gap between what the brand actually is and what the AI thinks it is matters more than the gap between languages.
This is the category label trap. It is a third source of dimensional collapse, distinct from the two we have already documented: training-data thinness (the brand AI has not read enough about) and geopolitical framing (the brand AI evaluates differently because of its perceived political context). Category translation failure is about something subtler: the brand has plenty of training data, the political context is not at issue, and the AI confidently produces a description that is structurally wrong because it has substituted the dominant template for the actual brand.
We measured this directly in the R15 experiment. Twenty-one thousand three hundred and fifty API calls across ten runs. Twenty-four large language models from seven training traditions. Twenty-three brand pairs across nine cultural traditions. The pattern shows up across every model family and every market.
We also ran a direct test of the obvious fix — swapping the comparator. The test produced a counterintuitive result: the swap made things worse, not better, for the hardest case. That finding is documented in the “Empirical test” subsection below.
How the trap works
Brand perception in AI mediation has two layers. The first is the brand’s actual position: what it sells, who it serves, how it operates. The second is the category template the AI activates when it sees the brand’s category label: the dominant exemplar the model has the most training data about.
For a Western brand, the two layers usually agree. When you ask an AI about Whole Foods, the activated template is Whole Foods — high-end organic, large stores, premium price point, founder mythology, Amazon acquisition, the whole structure. The AI’s template-matching is the brand’s actual position because the brand is large enough in the training corpus to be its own template.
For a non-Western brand sharing the same category label, the two layers diverge silently. The AI activates the same template — Whole Foods, Frito-Lay, Cadbury — and then describes the foreign brand using the activated template’s structure. The dimensional weights the AI assigns reflect what the template is, not what the actual brand is.
This is not a translation problem in the language sense. The AI is not failing to render Russian into English. It is failing to render VkusVill into VkusVill. The English-language description is fluent, confident, and structurally wrong.
Three case studies from the R15 dataset show what the failure looks like in practice.
Case 1: VkusVill is closer to Trader Joe’s than to Whole Foods
VkusVill is Russia’s clean-label private-label grocery chain. The company opened its first “Izbenka” store in 2009 in Moscow and now operates over 1,350 stores across 72 Russian cities, making it one of the largest organic-positioned chains in Eastern Europe.
The store-count number is misleading on its own. Whole Foods Market operates roughly 549 stores in North America, but those are large supermarket-format locations averaging tens of thousands of square feet, generating annual revenue around $17 billion. VkusVill’s stores are much smaller — closer to compact urban grocery format than to the supermarket footprint Whole Foods occupies — and the company’s annual revenue is roughly two orders of magnitude below Whole Foods. VkusVill is large for its operating model and its market; it is not “Russian Whole Foods” by any business-scale metric.
The structural model is not Whole Foods either, and that is the point. VkusVill operates a private-label-heavy assortment with a strong ready-to-eat meals component, smaller average store footprints, and higher inventory turnover. The customer is not a high-income wellness shopper buying premium organic produce; the customer is an urban professional buying convenient clean food at price points that cluster well below American “premium organic.” If you wanted a U.S. structural analog, the closest match is Trader Joe’s: private-label-dominant, smaller stores, higher turnover, distinctive own-brand identity, value-positioned within the natural-foods category. VkusVill is not exactly Trader Joe’s either, but the model space is closer to Trader Joe’s than to Whole Foods by every operational dimension that matters.
We paired VkusVill against Whole Foods in the R15 experiment as a category-mismatched supplementary pair. The dimensional weight profile that AI agents produced for VkusVill across 24 models was structurally indistinguishable from the profile they produced for Whole Foods. The AI was not evaluating VkusVill; it was evaluating the Whole Foods template with a Russian label attached. Cultural and Temporal dimensions — where VkusVill’s actual differentiation lives, in Russian urban quality-and-trust dynamics specific to its customer base — were among the dimensions that collapsed most severely.
We then ran a direct test: what happens if we swap the comparator from Whole Foods to Trader Joe’s? The result is in the empirical section below, and it is not what we hoped.
Case 2: Calbee is not Frito-Lay
Calbee is the dominant Japanese snack maker. Founded in 1949 in Hiroshima, the company makes vegetable crisps, jagariko fries, kappa ebisen shrimp crackers, and a continuously rotating catalog of seasonal limited editions that defines what “snack” means in the Japanese consumer experience. The product architecture is structurally different from American salty-snack brands: vegetable bases instead of corn, distinctive textures (puffed, crunchy, layered) instead of uniform crisp, umami rather than salt-forward seasoning, and a “kawaii” packaging aesthetic that the American snack category has no analog for.
The R15 experiment paired Japanese snack brands across the cross-cultural design. Japanese snack brands had the highest mean DCI of all nine cultural traditions tested — a Dimensional Collapse Index of 0.386, the most severe collapse in the entire study. Cultural meaning collapsed to roughly half of baseline. Temporal heritage collapsed similarly. The dimensions that constitute the actual differentiation of Japanese snack culture — the relationship to Japanese food traditions, the seasonal rhythm, the texture vocabulary, the aesthetic conventions — were the dimensions the AI flattened most aggressively.
The reason is not that AI lacks data about Calbee. Calbee is a large public company with extensive English-language coverage. The reason is that the category label “snack foods” activates the wrong template. Once the template is “potato chips and corn chips, Frito-Lay style,” the AI uses that template’s structure to evaluate Calbee. The fact that Calbee’s actual product line is built on vegetable bases, that texture variety is the differentiating dimension rather than flavor, that the seasonal limited-edition rhythm is constitutive of the brand experience — none of this survives the template activation. The AI describes Calbee using the language of Frito-Lay, and the description is not wrong in the sense of being false; it is wrong in the sense of being a description of the wrong company.
We tested a same-culture corrective comparator: Koikeya, another Japanese snack maker. The hypothesis was that pairing Calbee against a Japanese peer rather than an American category leader would relieve the template substitution pressure. The result is documented below.
Case 3: Roshen is not Cadbury
Roshen is Ukraine’s largest confectionery company. Founded in 1996, headquartered in Kyiv, the company operates a vertically integrated confectionery business spanning chocolate, biscuits, cakes, jellies, marmalades, and other categories. Roshen is not just a chocolate brand; it is a confectionery conglomerate that makes most of what fills a Ukrainian dessert table, under a single corporate roof.
Cadbury, the British analog the AI immediately reaches for, is a chocolate brand. Cadbury Dairy Milk, Cadbury Creme Egg, Cadbury Flake. Mondelez owns Cadbury and many other brands, but the Cadbury brand itself is a chocolate brand, not a confectionery conglomerate. When the AI sees “Roshen, confectionery, Ukraine” and activates the Cadbury template, it loses the conglomerate structure, the multi-category vertical integration, and the operational scale that distinguishes Roshen from a chocolate-only brand.
The closest American analog is not a single brand but a combination: Hershey for the chocolate, Nabisco for the biscuits, Dolly Madison for the cakes — all under one corporate roof. There is no clean Western brand template for “vertically integrated mid-sized national confectionery conglomerate.” The category label “confectionery” forces the AI to choose a template anyway, and the chosen template is structurally wrong.
This is not a story about geopolitics. We have written separately about the geopolitical signals in AI brand evaluation, and the Roshen results in that frame are striking on their own terms. But the category translation problem is independent of the political frame: even if Russia and Ukraine were not at war, even if Roshen had no political ownership, the category template for “Ukrainian confectionery” would still default to Cadbury, and the conglomerate structure would still be invisible.
We tested a multi-category U.S. corrective comparator: Hershey, which is more conglomerate-like than Cadbury. The hypothesis was that swapping Cadbury for a more structurally accurate analog would reduce dimensional collapse. See the empirical results below.
The pattern across the three cases
In all three cases, the failure mode is the same. The brand has a category label. The AI activates the dominant template for that category label — almost always an Anglophone brand that owns the category in English-language training data. The AI then describes the foreign brand using the template’s structure. The dimensions that distinguish the foreign brand from the template — the operational model, the customer relationship, the product architecture, the cultural context — are the dimensions that get flattened.
This is the third source of dimensional collapse we have documented in the R15 program:
Training-data thinness (H8 thin-data floor): brands AI has not read enough about. APU Chinggis, Mongolia’s national beer, is the canonical case. The hypothesis was that there exists a floor of collapse beyond which further information scarcity adds nothing. The hypothesis was not supported, but the underlying phenomenon was: when AI runs out of training data, it inflates verifiable dimensions and silently drops what it cannot verify.
Geopolitical framing (H12 supported, p < .0001): the same brand evaluated in different geopolitical contexts produces different dimensional weights. Roshen Moscow vs Roshen Kyiv produced the largest single effect in the dataset.
Category translation failure (this article): the brand has plenty of data, the political context is not at issue, and the AI substitutes a category template for the actual brand.
The three failure modes overlap empirically — VkusVill suffers from both (2) and (3); Calbee from (3) only; Roshen from (1), (2), and (3) — but they are conceptually distinct. A diagnostic that addresses one does not address the others. Translating your brand content does not fix category translation failure on home-market pairs (we tested this with the H10 native-language hypothesis: 121 model-pair comparisons in 11 languages, mean effect on collapse = +.001, p = .716, null result on the home-market case). Adding more training data does not fix it either: Calbee has plenty of data and still gets misread.
Empirical test: Run 10 corrective comparators
We predicted the corrective comparators would reduce DCI. They did not.
Run 10 (2026-04-10) tested whether swapping the comparator to a more structurally accurate analog reduces dimensional collapse for the focal brand. Design: three focal brands, two comparator conditions each (original “wrong” comparator as control; corrective comparator as treatment), seven models, three runs per cell. 126 API calls total. We measured Dimensional Collapse Index (DCI) across the Economic and Semiotic dimensions — the two most directly sensitive to template substitution.
Table 1: Run 10 DCI by comparator condition
A positive DCI delta means the corrective comparator produced more collapse, not less. All three brands moved in the wrong direction.
Table 2: Run 10 per-dimension delta (corrective − control)
The VkusVill result is the most striking. Pairing VkusVill against Trader Joe’s — the comparator we argued is structurally correct — produced a +7.4-point DCI increase. The Ideological dimension alone dropped by 5.952 points relative to the Whole Foods control. The only dimension that moved in the expected direction was Experiential (+.714). Swapping toward the “right” comparator made the overall collapse worse.
For Calbee and Roshen, the corrective comparators had negligible effects: +.713 and +.428, respectively. Directionally wrong but practically small. Neither the same-culture Japanese pairing nor the multi-category U.S. pairing disrupted the template substitution in a meaningful way.
What Run 10 tells us. The comparator does reshape the collapse pattern — the per-dimension deltas in Table 2 are real, not noise — but it does not cleanly fix it. In the VkusVill case, swapping toward a more accurate Western analog may have introduced a different template substitution problem: Trader Joe’s is a distinctive American brand with its own strong Ideological and Cultural signatures, and pairing VkusVill against it may have activated that template rather than clearing the evaluation of templates entirely. The AI is not performing a neutral relative comparison; it is evaluating each brand through whatever template the comparator activates. Changing the comparator changes the template that is activated, but does not eliminate template-mediated evaluation.
This is a more constrained diagnosis than we originally proposed. Comparator choice matters — it shapes which dimensions collapse and by how much — but the relationship is not monotonic in the direction we hypothesized. The structural fix has to work at a different layer.
What this means for non-Western brand strategy
The category translation trap has three practical consequences for any brand operating in a market where the dominant Anglophone category template misrepresents it.
First, the translation problem is bidirectional but asymmetric. The dominant template captures the dominant brand correctly. When AI evaluates Whole Foods, the template is Whole Foods. When AI evaluates VkusVill, the template is shaped by whichever comparator the AI activates at the moment of evaluation. The mismatch only goes one way: non-Western brands do not have the option of “becoming their own template” without first surviving the AI mediation layer that already exists.
Second, the conventional fixes do not work — and neither does the obvious new fix. Translating your website. Hiring local SEO consultants. Writing more content in your local language. Building backlinks from regional publications. None of these change which template the AI activates when it sees your category label. And as Run 10 shows, simply swapping the comparator in the evaluation context does not reliably reduce collapse either. The collapse happens inside the model’s weights, before any of your content — or any specified comparator — arrives with full leverage.
Third, the fix has to work at the specification layer, not the comparator layer. Run 10 shows that a corrective comparator embedded in the evaluation context reshapes the dimensional collapse but does not resolve it. What the comparator swap cannot do is give the AI a complete structural description of the focal brand’s identity independent of any template. That is what a machine-readable Brand Function specification does: it supplies the structural attributes — product architecture, customer model, operational format, cultural context — as first-order claims about the brand, not as relative claims anchored to another brand’s template. The corrective-comparator approach is a single field in a richer specification, and Run 10 suggests that field alone is insufficient. The broader specification context is doing work that the comparator field cannot do alone.
The brands that will survive AI-mediated commerce are not the brands with the most content in the most languages, nor necessarily the brands with the most accurately chosen comparator. They are the brands whose specification supplies enough first-order structural information that the AI agent evaluating them cannot default to a template because the template is structurally displaced by better data.
Why this matters even if your brand is “well-known”
A common objection: VkusVill, Calbee, and Roshen are not well-known to American consumers. Of course AI gets them wrong. My brand is well-known.
The argument fails for a structural reason. “Well-known to whom?” is the question that matters, and the answer is “well-known to the LLM that is mediating the consumer’s purchase decision.” Most non-Western brands that consider themselves well-known are well-known to their own market, not to the language-model that scrapes English-language web content. Calbee has a Wikipedia entry in English, a corporate website in English, and decades of trade press coverage. By the standard of “available in the training corpus,” Calbee is well-known. By the standard of “occupies its own template in the model’s perceptual structure,” Calbee is invisible — and the R15 data shows the cultural and temporal dimensions of its identity collapse to roughly half of baseline.
The category label trap is most severe for brands that are second or third in their category in the global English-language frame, regardless of how dominant they are in their actual home market. A Japanese snack maker that is the largest in Japan but the fourth or fifth in any English-language ranking gets evaluated through the lens of the first-ranked English-language brand in the same category. A Russian grocery chain that is among the largest in Eastern Europe gets evaluated through the lens of the largest English-language organic grocery chain. The position-in-the-template, not the position-in-the-market, is what determines how AI sees you.
This means almost every non-Anglophone brand that is not the global category leader has a category translation problem. The only brands that escape it are the ones large enough to be their own English-language template — Toyota, Samsung, Nestle, a handful of others. Everyone else gets the category template substitution by default.
The fix is structural, and it is not optional
Run 10 narrows the prescription. A corrective comparator alone — “we are X-type brand, not Y-type brand” — is not sufficient to break category template substitution, and in some cases (VkusVill vs Trader Joe’s) it introduces a new template substitution problem. The fix requires a broader structural specification: a Brand Function description that supplies first-order claims about the brand’s architecture, customer model, product logic, and cultural context, not just a relative positioning claim anchored to another brand.
For VkusVill, the substantive content is not “structurally Trader Joe’s, not Whole Foods.” It is: “VkusVill operates a private-label clean-food model with 1,350+ smaller-format stores and a strong ready-to-eat meals component. The customer is an urban professional, not a high-income wellness shopper. The Economic model is value-positioned within natural foods, not premium. Cultural positioning is grounded in Russian urban quality-trust dynamics, not Western wellness culture.” That is first-order structural description. The comparator, if included, adds context; it does not carry the load.
For Calbee: the specification names the vegetable-base product architecture, the seasonal limited-edition mechanic as a constitutive brand element, and the texture vocabulary that distinguishes the line — none of which the Frito-Lay template can supply by implication.
For Roshen: the conglomerate structure, the multi-category vertical integration, and the distinction from a chocolate-only template — described directly, not by analogy.
The Brand Function specification format that R16 describes is designed exactly for this kind of structural metadata. The corrective-comparator field is one component; Run 10 shows it is necessary but not sufficient on its own. The surrounding structural specification is the mechanism that changes what the AI agent “sees” when it reads your brand.
The cost is roughly thirty minutes of brand strategy work per brand — somewhat more than the “five words” framing we used before Run 10 results were available. The benefit is the difference between being read as your actual self and being read as a worse-positioned, smaller-market version of a foreign brand you do not resemble. For non-Anglophone brands, this is not a marginal optimization. It is the difference between visibility and invisibility in the channel that is now mediating most discovery.
Methodology: 21,350 total API calls across 10 runs (Runs 2-11). 24 models from 7 training traditions (Western, Chinese, Korean, Japanese, Russian, Arabic, Indian). Brand pairs spanning 9 country contexts (the seven training-tradition origins plus Ukraine and Mongolia). 23 brand pairs (10 global, 5 local from Cyprus, Latvia, Kenya, Vietnam, Serbia, plus 7 cross-cultural and 1 banking pair). 15 native languages plus English (999 native-language calls). Cross-model cosine similarity = .977. H10 (native language reduces collapse) null on home-market pairs (58/121 positive, mean = +.001, p = .716, two-sided), but Run 11 multi-city Roshen extension shows native language reduces collapse for foreign-context cities. Run 10 corrective comparator test: 126 API calls. Run 11 Roshen multi-city: 315 API calls. Total cost: ~$6.10 ($5.52 for the v2.0 9-run core, plus approximately $0.30 each for Run 10 and Run 11). Pre-registered hypotheses. Full methodology, data, and code: Zharnikov (2026v), “Dimensional Collapse in AI-Mediated Brand Perception.” Pre-print: doi.org/10.5281/zenodo.19422427. The category translation failure described in this article is documented across multiple brand pairs in the dataset; VkusVill, Calbee, and Roshen are illustrative cases, not the only ones. The full pair list is in experiment/L3_sessions/ in the R15 public repository.